IV. c_memmove▲
IV-A. Prototype▲
void * c_memmove (void * dest, const void * src, c_size_t n);IV-B. Description et comportement▲
Le nom de cette fonction peut porter à confusion car en effet, elle
ne déplace pas des données mais copie tout comme le fait c_memcpy
à quelques détails près !
La fonction c_memmove est à double usage ! Son comportement
est d'une part identique à celui de la fonction c_memcpy si
les blocs mémoire sont disjoints donc qui ne se chevauchent pas.
Là où les deux fonctions diffèrent l'une de l'autre, c'est que la
fonction c_memmove permet également de prendre en charge
des blocs qui se recouvrent partiellement donc qui se chevauchent !
La fonction c_memmove copie donc n octets de l'adresse
src vers l'adresse dest et retourne l'adresse dest !
IV-C. Algorithme▲
Voici un algorithme possible pour la fonction c_memmove:
algorithme
fonction c_memmove (dest:générique, src:générique, n:entier):générique
début
si src inférieur ou égal à dest alors
t1 <- src + (n - 1)
t2 <- dest + (n - 1)
tant que n <- n - 1 faire
dest[t2] <- src[t1]
t1 <- t1 - 1
t2 <- t2 - 1
ftant
sinon
c_memcpy (dest, src, n)
fsi
retourne dest
fin
lexique
dest : générique : Zone mémoire de destination d'un type quelconque.
src : générique : Zone mémoire source d'un type quelconque.
n : entier : Longueur de la copie.
t1 : entier : Variable de déplacement dans la zone mémoire src.
t2 : entier : Variable de déplacement dans la zone mémoire dest.
L'algorithme est ici un peu plus long que les autres car il faut
gérer deux comportements mais rien d'insurmontable. Dans la condition
logique, nous testons le chevauchement des zones mémoire. Si le
début de l'adresse src est inférieur au début de l'adresse
dest, il y a un risque de chavauchement des donnéees et donc,
pour éviter de corrompre la copie des octets, nous commençons par
la fin de la copie de longueur n !
Dans cette boucle, nous parcourons un à un les octets de l'adresse
src en partant de la fin...
Pour calculer la fin des adresses, on ajoute tout simplement la valeur de l'argument n à l'adresse de la zone à calculer puis on soustrait 1 pour débuter directement à la bonne adresse !
... puis on les copie dans la zone d'adresse dest. A chaque tour
de boucle il ne faut pas non plus oublier de décrémenter les variables
qui permettent le parcours (oui ici on décrémente car nous partons de
la fin jusqu'au début donc à l'envers).
Dans la seconde partie de la condition principale, nous appelons
tout simplement la fonction c_memcpy car le comportement
est alors identique, cela évite de programmer inutilement vu que nous
disposons déjà de cette fonction.
On termine la fonction en retournant l'adresse dest.
| Complexité temporelle dans le pire des cas: |
|---|
| Parcours simple de la boucle n fois: complexité en O(n) |
IV-D. Implémentation▲
void * c_memmove (void * dest, const void * src, c_size_t n)
{
char * p_dest = dest;
const char * p_src = src;
if (p_src <= p_dest)
{
p_dest += n - 1;
p_src += n - 1;
while (n--)
{
*p_dest-- = *p_src--;
}
}
else
{
c_memcpy (dest, src, n);
}
return dest;
}L'implémentation est à peu près identique à l'algorithme sauf qu'elle est adaptée aux pointeurs. Nous ne disposons donc pas de variables de parcours mais nous travaillons directement sur les pointeurs !
IV-E. Tests▲
#include "c_string.h"
#include <stdio.h>
int main (void)
{
char tab1 [] = "abcdefghijklmno";
printf ("tab1 = %s\n", tab1);
c_memmove (tab1 + 5, tab1 + 2, 7);
printf ("tab1 = %s\n", tab1);
return 0;
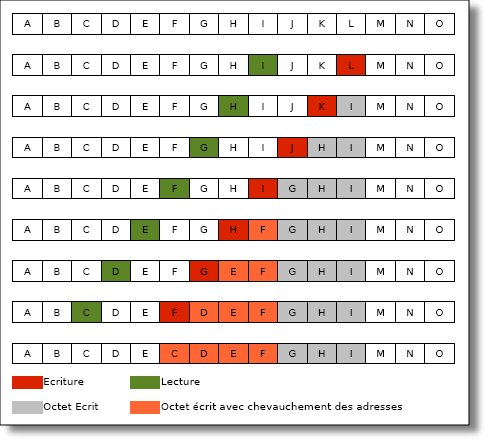
}Dans cet exemple vous pouvez effectivement observer un chevauchement partiel des blocs sur lesquels la fonction doit travailler et dans ce cas, elle va copier les n octets en commençant par la fin, voyons le résultat sur la console:
tab1 = abcdefghijklmno
tab1 = abcdecdefghimno
Process returned 0 (0x0) execution time : 0.015 s
Press any key to continue.Nous avons donc fait copier 7 octets en commençant par la fin, ce qui nous fait partir du bloc à l'adresse tab1 + (2 + 7) pour commencer à remplir à l'adresse tab1 + (5 + 7) et pour arriver en fin d'écriture à l'adresse tab1 + 5 ! Voici un schéma permettant de mieux visualiser le fonctionnement dans ce cas précis: